So I've just released a package called lazy-helper. This comes as lazy loading has been a hot topic once again due to the proposal PEP-810.
Using my package we can define lazy loaded dependencies nicely:
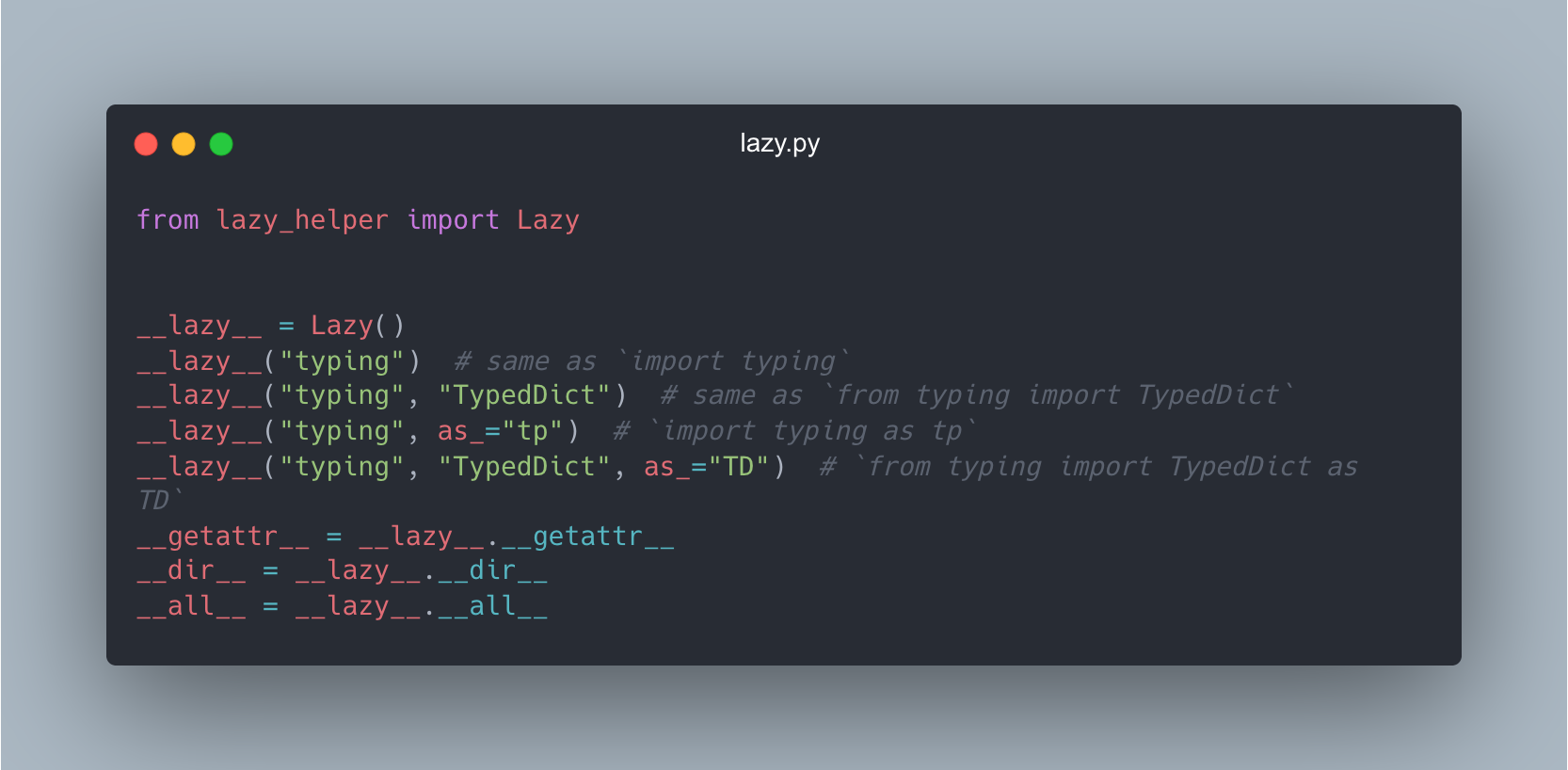
Coincidentally Brian Okken has recently written a blog post covering the topic of lazy loading where he goes over how it works. This is the same mechanism my package uses, essentially defining a module level __getattr__ with a cache. So I won't go into too much detail there.
Obscured static information
What I want to focus on discussing is one of the downsides of this approach. Since we're using strings to represent our imports, what is imported and where it points to is now obscured. This means when you use an import like the following:
from . import lazy
lazy.typing
Your editor or tools like mypy simply does not know where that leads to. Even worse, it doesn't even know if it's correct at all. If we have a typo like lazy.tpying we won't find out until runtime.
One way to provide this information is to manually specify this in a block like this:
if typing.TYPE_CHECKING:
...
from textual.widget import Widget
from textual.widgets._button import Button
from textual.widgets._checkbox import Checkbox
This is an example taken directly from textual which Brian discussed in his blog. Now your tooling understands the imports but at the cost of having to write this out manually. And we're still susceptible to typos and mistakes. So is there a better way to solve this?
Providing static information dynamically
This may sound a bit contradictory but we can leverage runtime information to solve our lack of static information.
Let's look at how Lazy is actually implemented:
from dataclasses import dataclass, field
type Alias = str
type ModuleName = str
type AttributeName = str
type LazyImport = tuple[ModuleName, AttributeName | None]
@dataclass
class Lazy:
imports: dict[Alias, LazyImport] = field(default_factory=dict)
def __call__(...):
"""Register the import"""
...
def __getattr__(self, name):
"""Run the import associated with the name"""
...
We can see that at its core, we are wrapping a dictionary which defines all the imports we are interested in. All the information is there when we load all the lazy imports. We just need a way to expose it to the static tooling.
Enter pyi files
.pyi files are what's known as stub files. They contain only typing information and used by static type checkers to infer the types without all the logic.
.pyi files takes precedence over the .py files they represent. So they can be used to type something that cannot be typed directly. It is quite often used for extension modules but also complex projects with a lot of legacy like boto3-stubs.
Similar to the if typing.TYPE_CHECKING: approach we can create a stub file with the correct imports:
# lazy.pyi
import typing
from typing import TypedDict
import typing as tp
from typing import TypedDict as TD
The difference is that we can now have the static typing information completely separate from the actual implementation. Making it a lot easier to programmatically generate these stub files.
We can generate the pyi files for the imports with a method like the following:
def stubgen(self):
for alias, (module, attribute) in self.imports.items():
full_path = f"{module}.{attribute}" if attribute else module
from_, _, import_ = full_path.rpartition(".")
import_ = f"{import_} as {alias}" if import_ != alias else import_
if from_:
print(f"from {from_} import {import_}")
else:
print(f"import {import_}")
print()
We'll then create a file with the printed code:
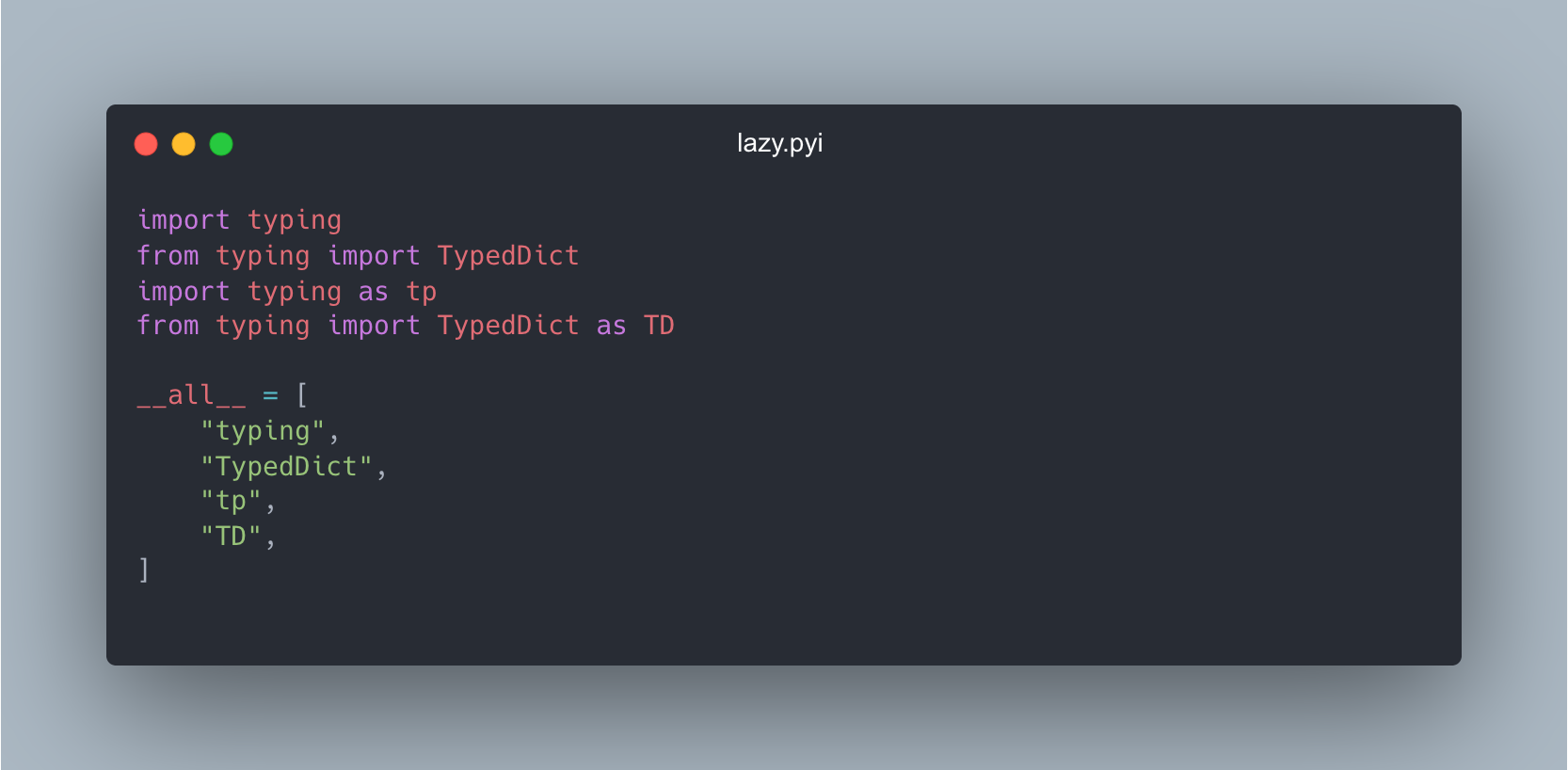
Since the stub file is generated from the runtime information. Your editor should pick up any issues typos or mistake in declaring the imports. It also saves a lot of effort as you don't have to write the stub manually.
For this reason, I've packaged a cli to simplify the process:
lazy-stubgen src/lazy.py
Stub generation is useful generally
Python is a very dynamic language, the language places very few limitations on what you can do. On the other hand, the static typing ecosystem is relatively new with a lot of limitations.
When the type system is inadequate for a problem, there are 3 things people usually try:
- Try to change the code and not use an advance feature.
- Try very hard to represent the typing as best as possible. This is sometimes known as type gymnastics.
- Or simply give up on trying to type the code.
I want to be clear here, all of these are valid. Stub generators are yet another way to solve this problem, It has the potential to provide typing with very little manual effort. What's important is to keep understand all the techniques available to you and to apply then when they are needed.
Here are some other examples in the wider ecosystem you should check out:
- MonkeyType a very tool that stores typing information as the code executes, to then generate static types afterwards.
- protoc protocol buffers are compiled into Python code with a mess of descriptors that is not type friendly, the compiler has a
--pyi_outoption to create the type stubs to solve this issue.